
MIPNet은 ICCV 2021에서 발표된 Human Pose Estimation에 관련된 논문입니다.
Human Pose Estimation 분야의 주요 method인 Top down method를 개선하기 위한 아이디어를 제공한 논문으로 상당히 좋은 적용성과 성능을 가지고 있어 주목해볼만한 논문입니다.
MIPNet의 핵심 아이디어를 먼저 한줄요약한 뒤에 세부설명을 드리도록 하겠습니다.
MIPNet
★ Key Idea : Top down method가 하나의 Bounding box 내에서 Multi instance를 인식할 수 있게 한다.
Top down method는 Object Detection 이후에 각각의 Bounding box에 대해서 Key Points Detection을 하는 순서로 이루어집니다. 이는 사실 Single person estimation을 반복하는것과 같다고 생각할 수 있습니다.

[Fig 1]을 보면, 두 사람의 Bounding box를 정하기 위한 Object Detection 이후에 각각의 사람에 대해서 Key points detection이 이루어지는 것을 알 수 있습니다.
하지만, 이러한 특징때문에 Top down method는 Person occlusion에 취약한 모습을 보여줍니다.
[Fig 2] 와 같이 하나의 Bounding box내에 두 명 이상의 사람이 존재할 경우, 앞의 사람의 Keypoint localizing만을 수행하는 것을 알 수 있습니다.
근본적으로 Top-down method는 하나의 Bounding box 내에 하나의 instance가 존재한다고 가정하기 때문입니다.
MIPNet은 Top down method가 근본적 한계를 극복하고, Bounding box 내 Multiple pose instance 를 인식할 수 있게 합니다.
MIPNet 성능
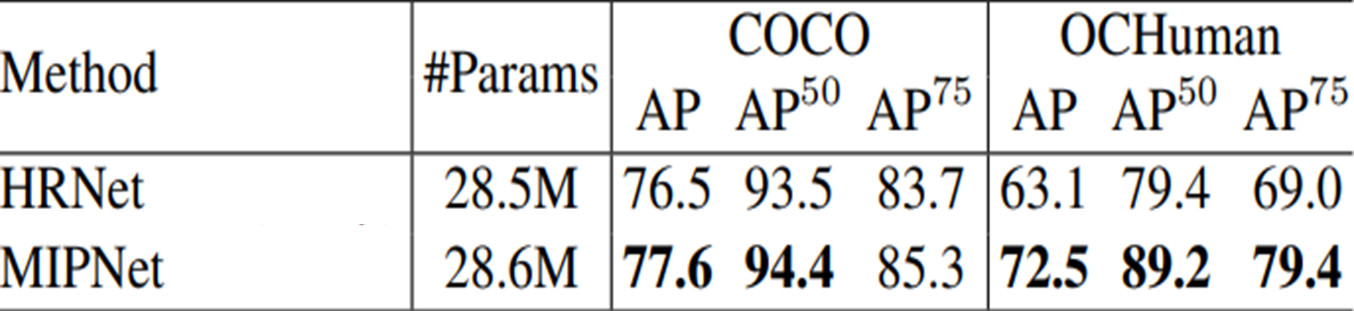
Top down method의 대표적인 model architecture인 HRNet과 한계점을 극복한 MIPNet의 성능을 비교한 [Table 1]입니다.
Person occlusion이 빈번하게 일어나는 Dataset일수록 더욱 좋은 성능을 보여준다는 것을 알 수 있습니다.
어떻게 MIPNet은 한계점을 극복할 수 있었을까요?
MIPNet은 input으로 image뿐만 아니라 lambda, λ라는 새로운 입력 변수를 받습니다.
MIPNet은 λ값의 변화에 따라서 Bounding box 내에서 앞의 사람을 인식할지 뒤에사람을 인식할지 결정할 수 있습니다.
λ값의 범위는 사전에 사용자가 지정한 N 값에 의해서 0≤ λ ≤N-1 의 정수로 결정됩니다. 여기서 N은 Bounding box 내에서 인식하게할 Instance Number를 의미합니다.
즉, 2명의 사람까지 인식하고자 하면, N=2, λ=0,1 이 되는 것입니다. MIPNet은 N값이 높아짐에 따라서 person occlusion이 빈번한 OCHuman에서는 좋은 성능을 보여줍니다.
하지만, trade off 관계에 놓여있으므로, N=2일때보다 occlusion이 적은 COCO 에서는 성능이 감소하는 모습을 보여줍니다.
Multi Instance Modulation Block, MIMB

MIPNet은 MIMB를 적용함으로써 기존의 Top down method model architecture를 개선합니다.
MIMB의 구조는 [Fig 3]을 통해서 알 수 있습니다.
X 는 Input Feature Map으로 채널 수 만큼 x1, x2, ..., xc 를 가지고 있습니다.
X`은 Output Feature Map으로 뒤에서 알아볼 과정을 거친 후에 채널 수 만큼 x`1, x`2, ..., x`c를 가지고 있습니다.
MIMP를 상단부터 세개의 파트로 나누어 알아보도록 하겠습니다.
1. Squeeze-Excite
Squeeze는 짜내다라는 뜻에 걸맞게, Input Feature Map에서 Global average pooling을 통해서 각 채널별로 특징값을 추출합니다.
Excite는 Two Layer Fully Connected Network로 weight를 갱신함으로써 Squeeze에서 추출한 각 채널의 특징값에 중요도를 매깁니다.
Squeeze-Excite는 참고문헌 2 Squeeze-and-Excitation Networks 에서 인용해온것이므로 해당 논문을 참고하면 이해에 도움이 됩니다.
2. Input
Input Feature Map입니다.
3. Embed
Embed는 Siple Neural Network로 앞서 살펴본 Excite와 아주 유사합니다. λ를 입력으로 받아서 채널로 분산시키는 역할을 담당합니다.
결과적으로 각 채널의 중요도에 대한 정보와, λ에서 받은 Instance selection이 Input Feature Map과 곱해지는 과정을 거치는 것이 MIMB입니다.
MIMB adopt
MIPNet의 가장 큰 장점은 기존에 존재하는 Top down architecture에 쉽게 adopt 될 수 있다는 점입니다.
[Fig 6]은 HRNet을 Backbone으로 하는 MIPNet입니다. 전체적인 architecture의 수정없이 단순히 MIMB를 adopt 하는 것만으로 비약적인 성능 개선을 이루어낸다는 것이 놀랍습니다.
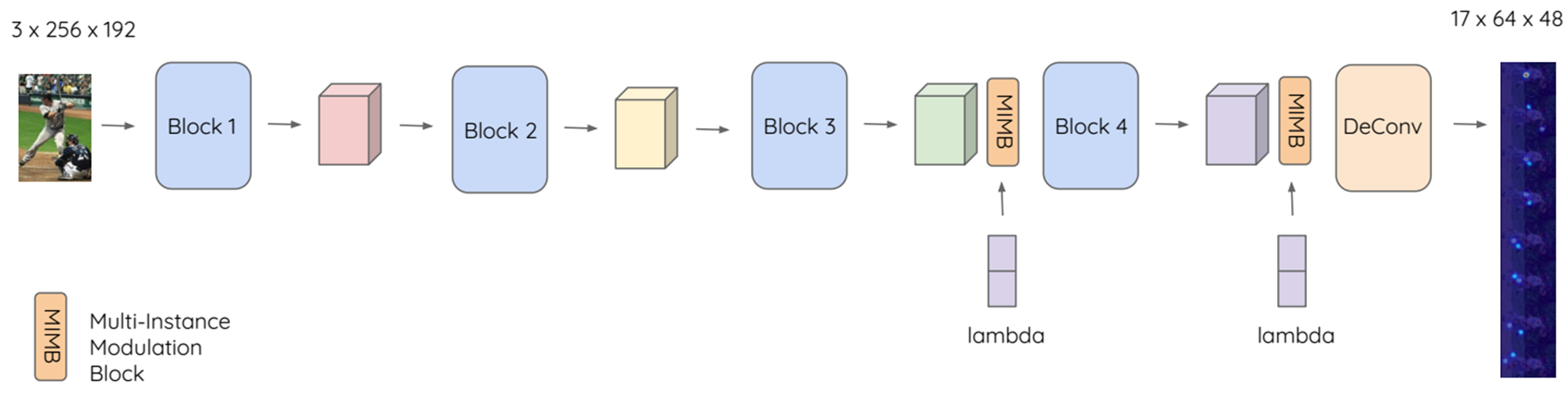
[Fig 7]은 또 다른 Top down architecture인 Simplebaseline을 Backbone으로 한 MIPNet입니다.
MIPNet 장점
MIPNet은 앞서 말한대로 Person occlusion에 매우 강한 모습을 보이도록 Top down method architecture를 개선합니다.
MIPNet이전에도 이러한 시도들이 있었지만, MIPNet이 특별한 이유는 비용적인 측면에 있습니다.
기존의 Occlusion 해결 방법들은 Instance 개수에 따라 Feature extractuon backbone을 N-fold increase 시키는 방식으로 구현되어 parameters 수가 너무 많이 늘어난다는 문제점이 있었습니다.
반면에 MIPNet은 3%정도의 Parameter 증가를 일으킬 뿐인 아주 효율적인 model입니다.
해당 포스트에는 개인적인 해석이 포함되어 있으므로, 수정할 부분이 있다면 말씀해주시기 바랍니다.
▲ 참고 문헌
Multi-Instance Pose Networks: Rethinking Top-Down Pose Estimation - Rawal Khirodkar, Visesh Chari, Amit Agrawal, Ambrish Tyagi (https://arxiv.org/abs/2101.11223)
Squeeze-and-Excitation Networks - Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu (https://arxiv.org/abs/1709.01507)
Residual Block from ResNet - pytorch
Residual Block from ResNet - pytorch
Residual Block은 2015년 발표된 paper "Deep Residual Learning for Image Recognition" 의 model architecture인 ResNet의 주요 아이디어 입니다. ResNet은 2015년 COCO competitions 를 비롯한 Computer Vision..
gamdonge.tistory.com